Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 134
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 135
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
|
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 157
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 158
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 159
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 160
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 161
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 162
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 163
 |
4D Multi-View Capture
The video shows some examples of the multi-view capture system used to built the 4D Facial Dynamics Database.
Several individuals performing different facial expressions (p.e. angry, contempt, disgust, fear, happy, sad, surprise and neutral) as well as the phrase 'yes we can' were recorded by our capture system.
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 151
|
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 250
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 251
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
|
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 276
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 277
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 278
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 279
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 280
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 281
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 282
 |
Efficient Simultaneous Forwards Additive (EFSA) Fitting Algorithm
The 2.5D Active Appearance Models (AAM) combines a 3D shape model and a 2D appearance model.
It has both 3D data and 2D image componets, hence the 2.5D designation.
The video shows the 2.5D AAM fitting in a video sequence using the Efficient Simultaneous Forwards Additive (ESFA) algorithm.
Each image show the input frame overlaid with the projected mesh and tree different views of the current 3D shape.
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 276
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 277
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 278
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 279
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 280
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 281
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 282
 |
Model Fitting in the 3D Dynamic Facial Expression Database (BU-4DFE)
The video shows the 2.5D AAM model fitting (ESFA algorithm) in a subset of the BU-4DFE dataset.
The 3D structures (shapes) were recovered using the Efficient Simultaneous Forwards Additive (ESFA) algorithm.
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 276
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 277
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 278
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 279
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 280
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 281
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 282
 |
Image Alignment in the IMM Face Database
Discriminative/Generic face alignment the IMM database using the DBASM-KDE approach.
The Kernel Density Estimator (KDE) suffix means that the local response maps are non parametrically approximated.
The videos shows the fitting within each iteration at the image reference (left), the KDE landmarks update in the normalized frame (using the mean-shift algorithm - in center) and the uncertainty covariances at each landmark (right).
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 276
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 277
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 278
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 279
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 280
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 281
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 282
 |
Generic Face Alignment in the Labeled Faces in the Wild (LFW) Dataset
Qualitative model fitting evaluation in the challenging Labeled Faces in the Wild (LFW) dataset using the generic image alignment algorithm: Discriminative Bayesian Active Shape Models (DBASM-KDE).
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
|
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 250
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 251
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
|
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 276
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 277
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 278
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 279
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 280
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 281
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 282
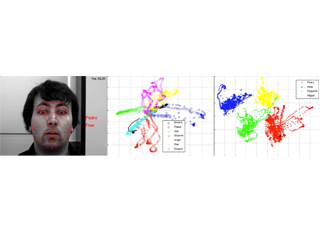 |
Identity and Facial Expression Recognition
Examples of identity and expression recognition using our system.
The recognition is based on a two step approach, first the identity is predicted by Support Vector Machines and then the facial expression is recognized using a network of Hidden Markov Models.
The video shows the AAM fitting process (feature extraction) at the left image, the projection into the identity manifold (represented as the black dot at right image) and the trajectory in the expression manifold (black path at center image).
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
|
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 250
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 251
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/phpFunctions.php on line 95
|
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 276
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 277
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 278
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 279
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 280
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 281
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 282
 |
Tracking Performance in the FGNET Talking Face Video Sequence
Bayesian Active Shape Model (BASM) tracking performance evaluation in the FGNET Talking Face Sequence.
The video evaluates several discriminative image alignment algorithms, namely: Active Shape Models (ASM), Convex Quadratic Fitting (CQF), Bayesian Constrained Local Model (BCLM), Subspace Constrained Mean-Shifts (SCMS) and our Bayesian Active Shape Models (BASM) formulation (including the Hierarchical version BASM-H)
|
Warning: Use of undefined constant projectID - assumed 'projectID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 270
Warning: Use of undefined constant demoID - assumed 'demoID' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 276
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 277
Warning: Use of undefined constant thumbnail - assumed 'thumbnail' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 278
Warning: Use of undefined constant fileFLV - assumed 'fileFLV' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 279
Warning: Use of undefined constant fileAVI - assumed 'fileAVI' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 280
Warning: Use of undefined constant description - assumed 'description' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 281
Warning: Use of undefined constant showOnDemos - assumed 'showOnDemos' (this will throw an Error in a future version of PHP) in /var/www/html/demos.php on line 282
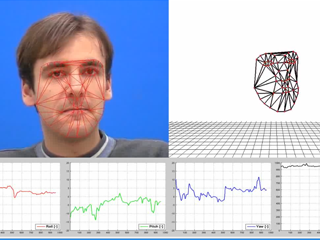 |
Pose Estimation in the FGNET Talking Face Video Sequence
Pose estimation in the FGNET Talking Face Sequence using the 2.5D AAM.
Qualitative 3D shape recovery is presented in the right.
The graphics show the estimated roll, pitch and yaw angles (in degrees) and distance (in mm) to camera.
The ERSFA fitting algorithm was used in the experiments.
|
|
|